
This is the second of two blog posts on emission factor normalization. In this blog, we will explain what the normalization process looks like at Climatiq specifically. To get a broader understanding of what normalization is and why it’s necessary in carbon accounting, check out our first blog post.
There are hundreds of datasets within the carbon accounting space. They come from a range of sources spanning across the globe, such as governmental bodies, NGOs, and academic institutions—each with thousands of emission factors which often relate to a specific geography or industry.
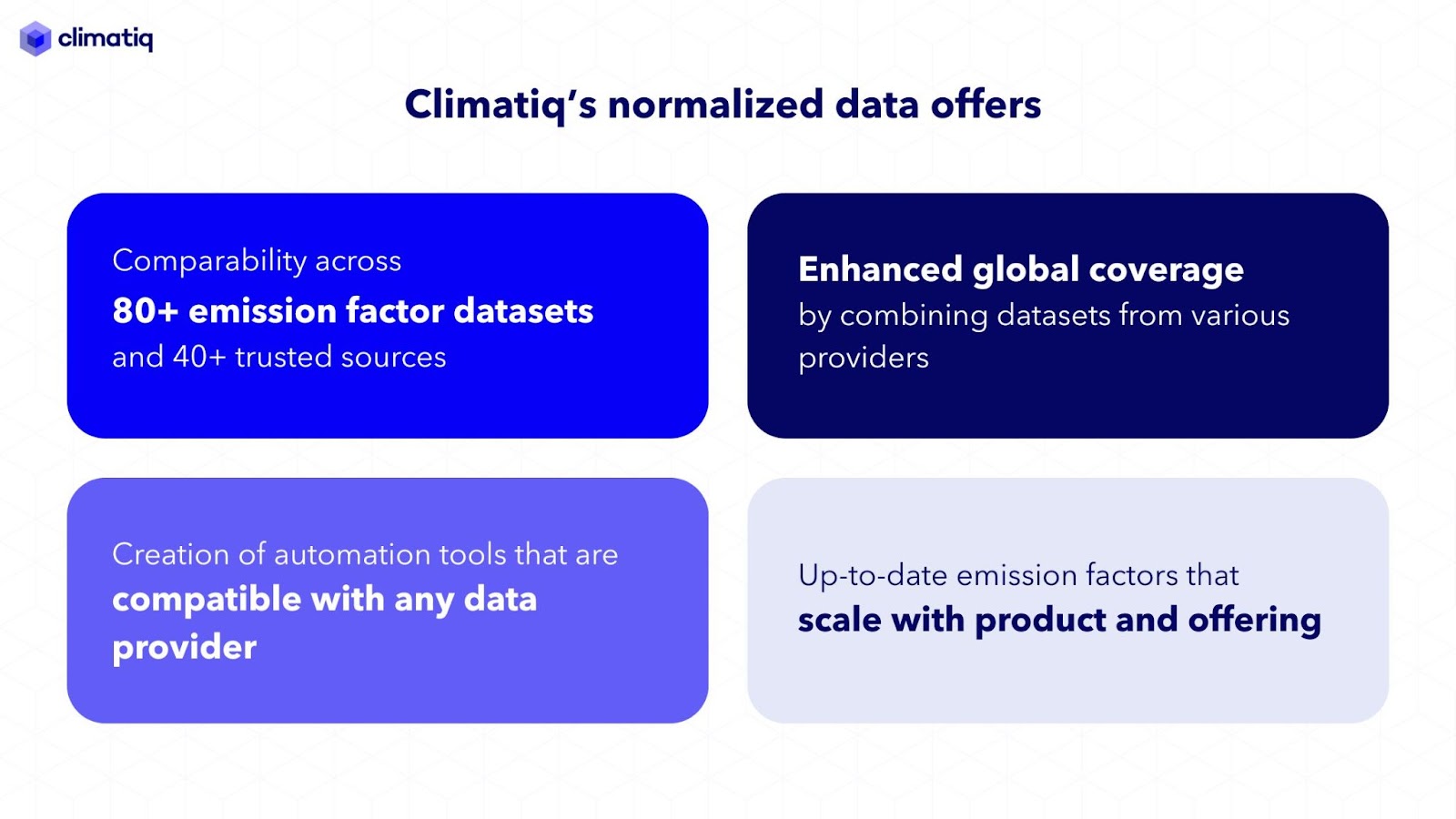
At Climatiq, we have normalized over 600,000 (and counting!) emission factors from different datasets and for different regions by adjusting or removing variables that could introduce bias or hinder comparability. This allows users to quickly build robust emissions tracking tools on top of our database, avoiding the time and cost involved with building a bespoke dataset.
The normalization process involves aligning naming (unifying wording or spelling), standardizing units (e.g. by converting weight from pounds (lbs) to kilograms), and clearly labelling the scope of emissions being measured (such as whether they cover a product’s entire lifecycle or just part of it). This allows our users to access data in an automated system without having to worry about comparability and compatibility.
By normalizing emission factors into our cohesive schema, we provide a trusted, transparent, and accessible resource which makes it easy to use emission factors from various sources and apply them in programmatic calculations.
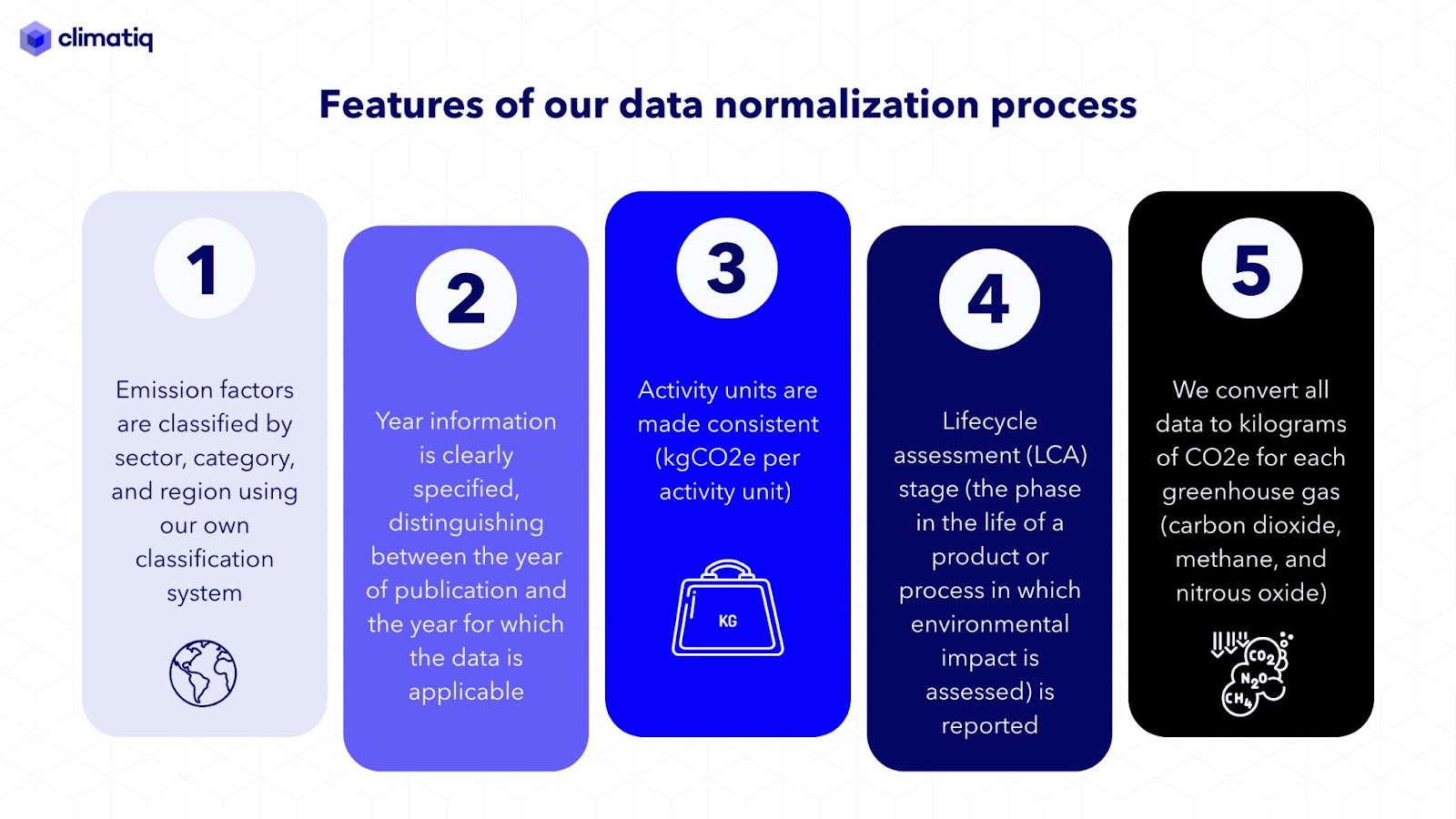
Normalization is part of our wider data ingestion process, which also involves analyzing metadata, adding quality flags, and expert manual review by our Science and Data team of PhD-educated scientists and carbon accounting experts.
All of this is done to allow our customers to:
This harmonization allows users to quickly build reliable, globally applicable emissions tracking capabilities. Rather than spending months sourcing and cleaning data, they can simply integrate Climatiq’s database and trust that emission factors are reliable, current, and maintenance-free, saving time and resources for wider product development.
Some sources provide the values for CO2, CH4, and N2O in their actual weight (in kilograms), while others report them in kilograms of CO2e (CO2 equivalent—which reflects their climate impact rather than their actual mass). For example, in the BEIS dataset, the values for CO2, CH4, and N2O are given in kg CO2e. This means the data has already been adjusted using Global Warming Potential (GWP) factors, which show how much each gas contributes to global warming compared to CO2.
However, since we collect and report the actual amount of each individual gas, we had to convert the CO2e values back by dividing them by their respective GWP values based on the IPCC method used.
We normalized electricity data from these three different sources to use the same name, activity_id, and lca_activity because they all refer to the same type of activity. This is done to ensure consistency between datasets and allow for comparability.
The original units:
To make the data comparable, all values were converted to a common unit: kg/kWh.
In the original EPA dataset, the term “Coal and Coke” is used. We standardized the name to “Coal - anthracite” to match naming conventions in other datasets and to ensure it's searchable in the Data Explorer along with similar activities.
Managing huge amounts of emissions data is a question of balancing breadth and consistency. If we only used a single data provider, we'd have great consistency but our users would be far more limited by data coverage and granularity. Many of our users operate globally or build tools to measure emissions across entire supply chains and business activities, so they require data that’s both wide-ranging and compatible with their software.
Sourcing this data is already a massive task in itself, before even tackling the complex work of normalizing the data to make it comparable and usable. Our database bypasses this, ensuring you have access to the widest range of accurate emission factor data—all in one place—without the consistency issues of a patchwork dataset.
To find out more about our data and calculations, check out our Methodology Hub.


.svg)
